Hendelsesbasert provisjonering
Detaljer om integrasjonsmønsteret "hendelsesbasert provisjonering".
Dette er et integrasjonsmønster som anbefales brukt ved provisjonering mellom to systemer.
TODO: Skriv...
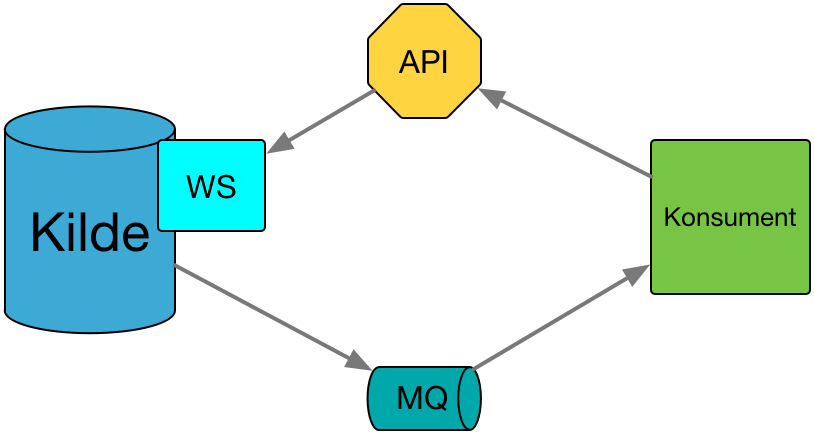
Vanlig flyt:
- Kildesystemet får endret data om en entitet, for eksempel ved saksbehandling.
- Kildesystemet sender ut en notifikasjon om at entiteten er blitt endret.
- Meldingskøen tar i mot notifikasjonen og distribuerer den ut til alle konsumenter som abonnerer på denne typen notifikasjon.
- Konsumenten mottar notifikasjonen, og ser om den er relevant.
- Konsumenten henter ut data fra kildesystemet sitt API
- Konsumenten oppdaterer interne data med oppdaterte data fra tilbyderen.
Hvis konsumenten selv er tilbyder av andre kildedata, som blir oppdatert basert på dette, vil konsumenten bytte rolle og gå gjennom samme prosessen. Et eksempel er at en navneendring i HR-systemet vil kunne føre til at e-postadressen også vil måtte endres. HR er kildesystem for navn, og IGA kan være kildesystem for e-postadresser.
Et tenkt eksempel fra flyten over:
- Kilde sender notifikasjon med innhold "person 123 er endret" til MQ som følge av at et telefonnummer er endret.
- MQ videresender notifikasjonen til de konsumenter som abonnerer på denne typen notifikasjoner fra kilden.
- Konsumenten får beskjed om at person 123 har en ukjent endring.
- Konsumenten kontakter API manager, som styrer tilgangen til WS-en til kilden, for å spørre om personobjektet 123.
- Alle kall til API manager, og som er forhåndsgodkjent, videresendes til WS-en.
- WS-en returnerer personobjektet 123, med det oppdaterte telefonnummeret.
- Konsumenten lagrer telefonnummeret.
Når bør dette brukes?
Dette mønsteret passer når du trenger å provisjonere et endesystem med kildedata fra en tilbyder, uten at sluttbrukeren er involvert.
Dette mønsteret bør brukes når noen forventer at data er tilgjengelig tilnærmet umiddelbart, eller når fortløpende oppdateringer gir en bedre brukeropplevelse.
Fordeler
Data blir oppdatert raskere i mange systemer - "tilnærmet umiddelbart".
Mye mindre ressurskrevende enn det eldre mønsteret der du henter alle data fra kilden, og oppdaterer konsumenten.
Ulemper
Passer best for system-til-system-integrasjoner.
Har du veldig mange konsumenter vil det sette høyere krav til ytelsen hos tilbyderen. Dette kan kompenseres ved for eksempel caching i API manager.
Å implementere notifikasjonsutsending kan vere krevende å implementere. Det kan også være ukjent teknologi for utviklere.
Fallgruver
Kildesystemet bør bare sende ut notifikasjoner når data faktisk er endret, og ikke sende ut notifikasjoner bare fordi tjenesten har mottat notifikasjoner fra andre. Falske positive notifikasjoner vil føre til mer ressursbruk, siden tjeneste sender ut notifikasjoner som kan føre til unødvendige API-oppslag fra konsumenter. I verste fall vil du kunne få evige meldingsløkker hvis to systemer som snakker sammen gjør samme feilen - de vil sende samme notifikasjonen fram og tilbake.
Se også
TODO: Gammel:
Hendelsesbasert oppdatering
Provisjonering – Need to Know
Provisjonering er det å sende en mengde data fra en applikasjon til en annen. Hvorfor man ønsker å gjøre dette kan være mange, men tradisjonelt har man basert integrasjoner på provisjonering fordi integrasjoner har vært tunge, filbaserte batch-oppdateringer. Man har laget store filer med komplette datasett, flyttet disse til konsumenten og der sammenligner man den store filen med konsumentens database for å se etter endringer. Dette er ikke en effektiv måte å integrere på. Isteden kan slik provisjonering være hendelsesdrevne:
En entitet X oppdateres i Kilde. Kilde sender en notifikasjon til MQ om at entitet X er oppdatert. MQ sender en notifikasjon til konsumenter som abonnerer på denne typen notifikasjoner om at entitet X er oppdatert. Konsument vet ingenting om hva endringer består i, så Konsument kontakter API manager for å få tilgang til Kildens WS for å spørre om data om entitet X.
Mange applikasjoner, som i dag er baserte på gamle integrasjoner med provisjonering, trenger ikke å provisjonere data i den nye arkitekturen. Likevel er det et behov for provisjonering i de tilfeller der man lager moderne applikasjoner og integrasjoner. Eksempel: Når en ny person registreres i HR-systemet så er ikke HR-systemet ansvarlig for å utstede en brukerkonto til personen. Dette er IAM-kjernen (tidligere BAS, IdM) ansvarlig for. IAM-kjernen vet ikke at det er registrert en ny person i HR-systemet før HR-systemet gir beskjed. IAM-kjernen vil ikke kopiere alle data om personen fra HR-systemet, men den trenger data om personen for å lage en brukerkonto til vedkommende og da vil IAM-kjernen provisjonere noe data. IAM-kjernen vil beholde oversikt over hvem som er eier for brukerkonti f.eks. Disse eierne er provisjonert fra HR-systemet.
Man kan tenke seg et annet eksempel der flyten er lik som i figuren over, men man ikke provisjonerer – integrasjonen er basert på Need to Know. Forskjellen på provisjonering og Need to Know ligger i om konsumenten lagrer kopier av data fra kilden i sine datalagre. Distinksjonen mellom de to er minimal, men generelt skal man forsøke å unngå mellomlagring av data fra et kildesystem og heller hente disse dataene fra kilden ved behov. Av ulike årsaker kan dette vise seg vanskelig så provisjonering vil forekomme også i den nye arkitekturen.
Forskjell fra DiFis eNotifikasjon
Selv om Need to know kan ligne veldig på eNotifikasjon-mønsteret fra DiFis referansearkitektur for datautveksling, er det til dels store avvik i mønstrene:
| Need To Know | eNotifikasjon | |
|---|---|---|
| 1 | Får tilsendt en notifikasjon. |
Konsumenten kan være tilstandsløs, da konsumenten ikke trenger å ha begrep om hvilke notifikasjoner som er prosessert.
| Må hente en liste over notifikasjoner.
Konsumenten må lagre tilstand, da eNotifikasjon-mønsteret forutsetter at konsumenter vet hvilke notifikasjoner som er prosessert.
| | 2 | Notifikasjonen inneholder kun nok informasjon til å identifisere hva som har endret seg.
Konsumenten må utføre eOppslag mot kildesystem før det kan avgjøres om det skal utføres en operasjon.
| Notifikasjonen inneholder informasjon om hva som har endret seg, og en identifikator til et hendelsesdokument som inneholder endrede data.
eNotifikasjonen bærer nok data til å avgjøre om det skal utføres en operasjon.
| | 3 | Rekkefølgen notifikasjoner ankommer i er ikke garantert å være velordnet og sekvensiell. | Rekkefølgen notifikasjoner ankommer i er alltid velordnet og sekvensiell. | | 4 | Ingen autorisasjon er nødvendig da notifikasjoner kun har informasjon om hva som er endret. Produsenter har ikke begrep om hvem som er konsumenter. | Autorisasjon kan være nødvendig da notifikasjoner kan inneholde data.
I tilfeller der autorisasjon er nødvendig, må produsenter ha et begrep om hvem som skal kunne konsumere hvilke data. | | 5 | Need To Know er en implementasjon av Fire And Forget og eOppslag mønstrene. | eNotifikasjon er en implementasjon av Event Sourcing mønsteret. |